SAM 和 Visual Prompting 对 Data-Centric AI 的启示
文章目录
整个 23 年上半年,NLP 领域的变化可谓如火如荼,那 CV 方向尤其涉及模型开发的工程架构领域发生了哪些变化?因此有了下面两个简单的调研:
Ⅰ、Segment Anything Model
结论先行:SAM 研发过程是一次 CV 领域对 Data-Centric AI 思想实践的优秀案例,SAM 的出现也许会对 CV 领域 Data-centric AI 带来一次范式升级
观点1:从过程层面,SAM 的研发过程是一次 CV 领域对 Data-Centric AI 思想实践的优秀案例
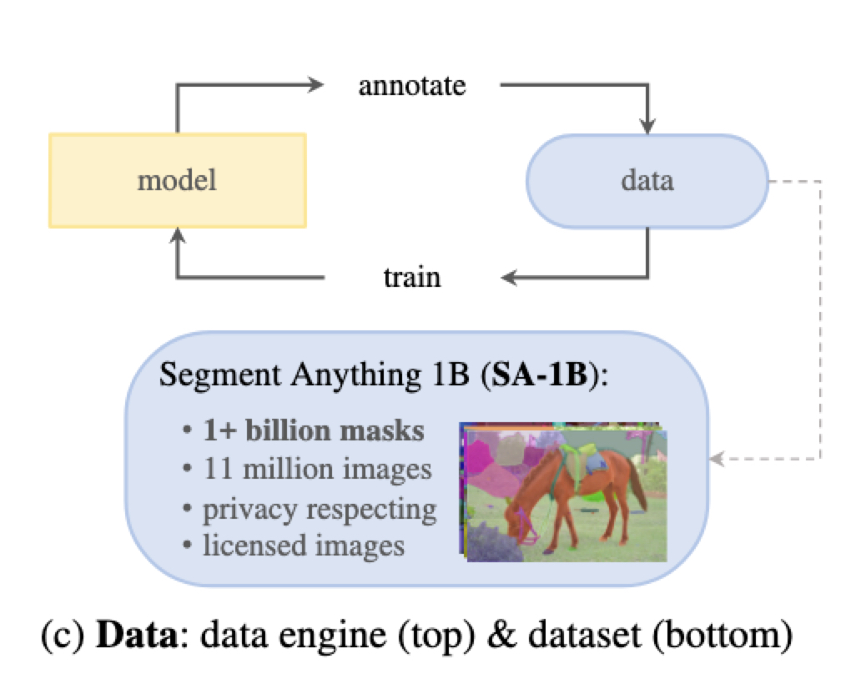
SAM 的论文中提到他们做了一个所谓的 数据引擎 ,基于这个数据引擎产生了 SAM 模型训练的数据集 SA-1B(1 Billion 的标注结果,涉及11 Million 图片),接下来我详细描述下数据引擎的三个阶段:
-
阶段 1、模型来辅助人工标注
- 过程概述:类似主动学习(Active learning)的过程,基于浏览器的标注工具来实现交互式体验。先用公开数据集训练一个初始模型,然后预测数据集的 Mask(相当于模型先标注一轮,本质是降低单个标注动作的难度),再让标注人员对标注结果进行修改,然后仅使用新标注的数据对模型进行训练。以上三步总共重复了6轮。
- 阶段性成果:
- 标注效率:掩码(Mask)的平均标注时间从 34 秒降低到 14 秒
- 数据集:
- 每张图片的平均掩码(Mask)数量从 20 个增加到 44 个
- 从120K图片集中收集到了 430 万个掩码(Mask)
-
阶段 2、半自动标注
- 过程概述:这个过程的目标是提升收集的掩码(Mask)数据的多样性。本质还是一个主动学习(Active learning)的过程,方法就是让模型标出一些置信度比较高的 Mask,然后让标注人员专注在这张图片上未被模型标注的 Mask上(区别于阶段一,这里对效率的改变其实是通过降低待标注 object 量来实现的)。为了获得模型标注的置信度结果,他们利用阶段一产生的数据训练了一个 边界框检测器(bounding box detector),用这个模型来做置信度检测筛选高置信度 Mask。该过程重复了 5 轮
- 阶段性成果:
- 标注效率:掩码(Mask)的平均标注时间从阶段一的 14 秒回到了 34 秒(不含自动标注),因为这些标注更难了
- 数据集:
- 每张图片的平均掩码(Mask)数量从 44 个增加到 72 个
- 180k张图像中额外收集了 590 万个掩码(Mask),加上阶段一的数据,累计 1020 万个掩码
-
阶段 3、全自动标注
- 过程概述:进入全自动标注的状态,主要得益于两点。一是前一个阶段收集了足够的数据来改善模型的性能。二是他们开发了模糊感知模型,即使在模糊场景也可以有效预测(结合附录 B 的描述,我理解这里的模糊感知模型应该就是附录提到的那个专门用来实现自动标注的特殊版本的 SAM 模型,这个模型训练时只使用了人工和半自动标注数据,牺牲了推理速度来提升改善 Mask 生成能力,训练时间更长,使用大规模抖动数据增强等等)
- 阶段性成果:
- 标注效率:完全自动化
- 数据集:SAM 的完整训练数据集 SA-1B 出现。该阶段在 1100 万张图像上使用全自动标注,总共生成了 11 亿个高质量掩码,生成了 SAM 的训练数据集SA-1B(没有和阶段一和阶段二的数据做整合,前两个阶段数据看起来只是为阶段三服务的)
观点2:从结果层面,SAM 的出现也许会对 CV 领域 Data-centric AI 带来一次范式升级
受 NLP 领域的启发,Meta 的团队通过 SAM 实现了 CV 领域的 Pre-train Model + Prompt
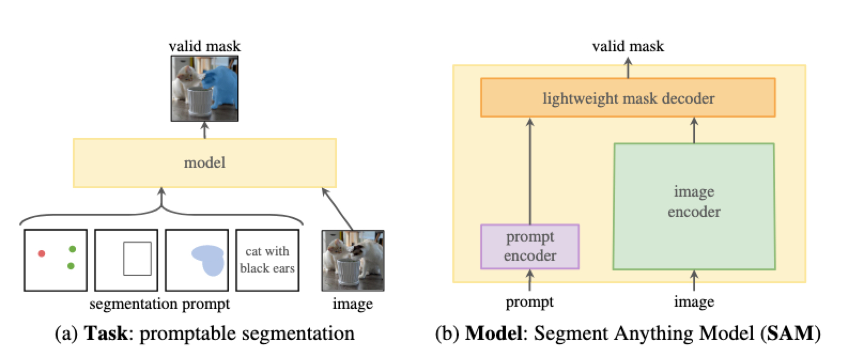
- Prompt 介绍:SAM 里的 Prompt 可以是一组前景/背景点、粗略框或掩码、自由格式文本,或者通常是指示在图像中分割什么的任何信息(评测结果显示点、框和掩码效果更好,其他例如文本还不理想)
- 预训练的目标任务:算法模拟每个训练样本的提示序列(例如,点、框、掩码),并将模型的掩码预测与 ground-truth 进行比较
模型总览
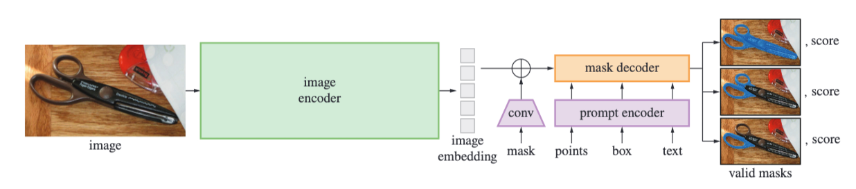
SAM 通过一个重量级的图像编码器输出一个图像嵌入(embedding),然后可以通过多种输入提示(mask、points、box、text)来平摊生成目标掩码的实时速度实现高效查询。对于对应多个对象的模糊的提示,SAM 可以输出多个 valid masks 和对应的置信度分数。
个人理解,SAM 的出现确实可以称得上是突破性的,一方面它为后续各种任务场景的 fine-tune 提供了 foundation model,另一方 SAM 本身就可以被应用于辅助标注,甚至可以参考他们 数据引擎 的思路,直接使用 SAM 作为冷启动模型来解决一些目标检测识别的 CV 任务。
Ⅱ、Visual Prompting @Landing AI
04月26日 Data-Centric AI 的布道师 Andrew ng 通过直播的形式在其创业项目 Landing AI 上发布 Visual Prompting 的产品功能,虽然还只是一个试用版本,但是可以明确的是这是一次 Prompt 在CV 领域数据标注甚至 Data-Centric AI 的一次产品化的尝试
先简单介绍 Landing AI,再详细描述下这里的 Visual Prompting 的效果和思想理念
Landing AI 简介
Landing AI 是由 Andrew ng 创立,致力于践行 Data-Centric AI 来实现 AI 的商业价值,其旗舰产品是 LandingLens,致力于 makes computer vision easy for everyone
Landing lens 试用
Landing lens 其实就是一个 CV 领域 Data-Centric Workflow,让用户可以以最简单的方式实现(或者只是冷启动)一个视觉模型的研发 loop(提升数据质量来提升模型性能的研发回环)
工作流程:典型的 Data-Centric 流程

本人找了10张(项目要求最少10张)摩托车图片尝试了下这个流程,先框选标注下数据,然后点击按钮训练即可(全程耗时几分钟)
训练过程数据如图(并不知道实际用了什么算法)
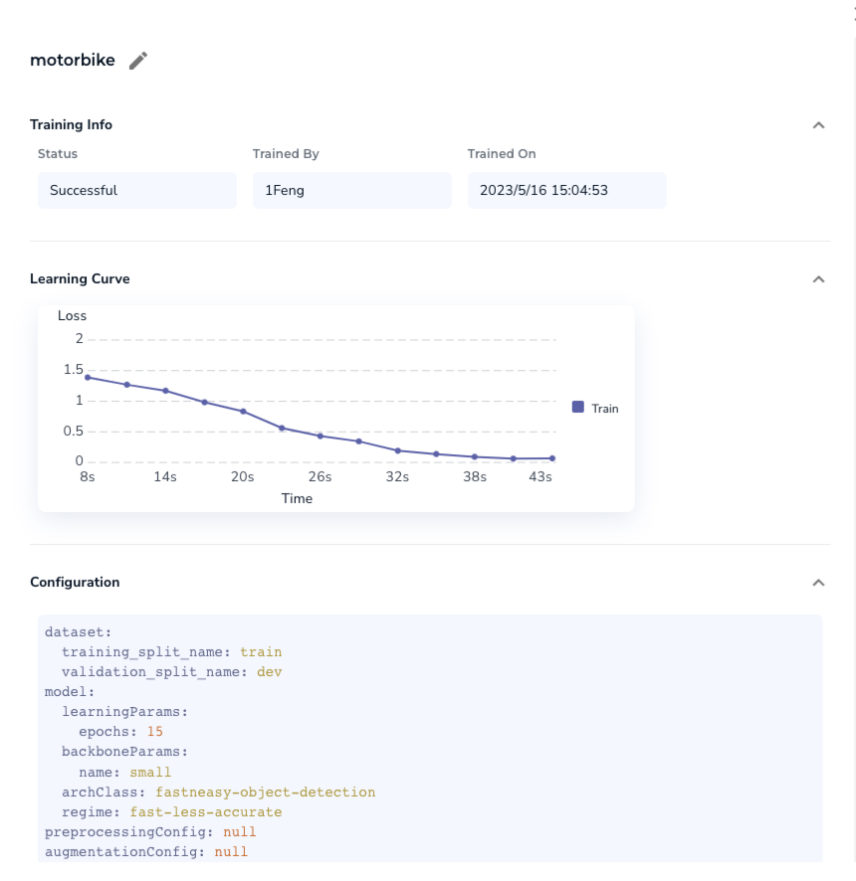
Visual Prompting 介绍
先说结论,Visual Prompting 就像是把 SAM 模型应用到了数据标注领域来驱动 Data-Centric AI 的一次产品实践
Visual Prompting 是作为 Landing AI 旗舰产品 Landing Lens 的一个子能力来落地的。(目前选择 Visual Prompting 的项目类型,还只能使用他们的 demo 数据集来试用,无法使用上传数据,估计是产品功能还只是个 demo 阶段)
接下来是我个人试用的描述:
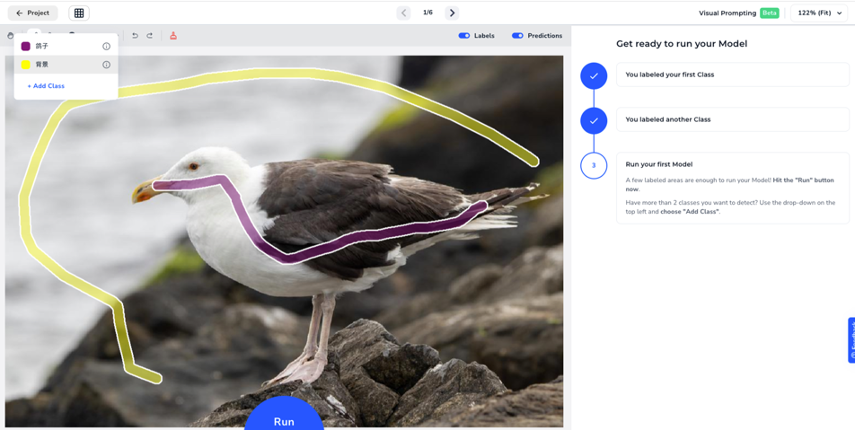
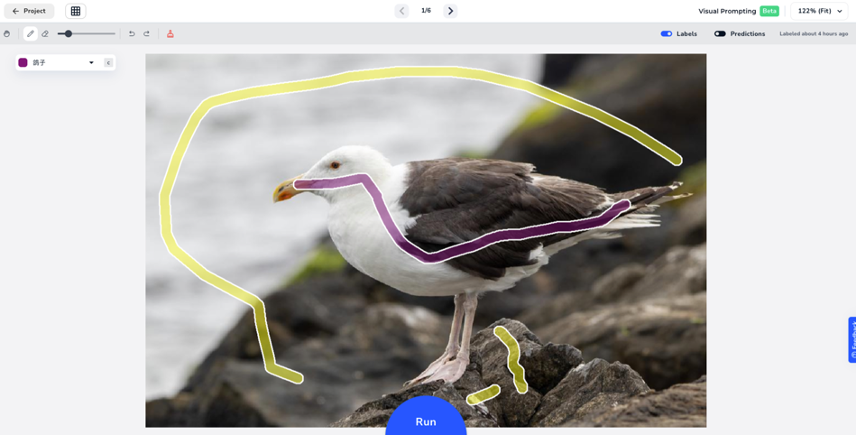
以标注图片里的鸽子为例,设置两个 Prompt 的线条,紫色代表鸽子、黄色代表背景,然后在不同区域用不同线条勾画下
点击 run 按钮,直接完成了目标的分割,如下图
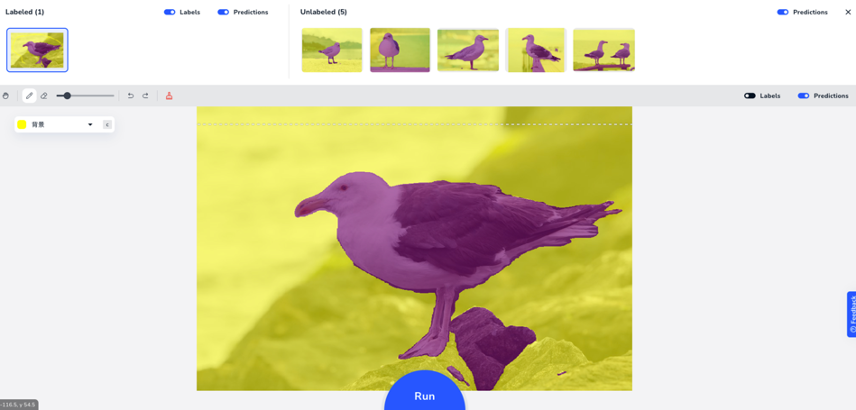
下面有一块石头其实是背景,被识别成了鸽子,所以可以再用 Prompt 线条调整下,点击run(秒级),结果如下图 :
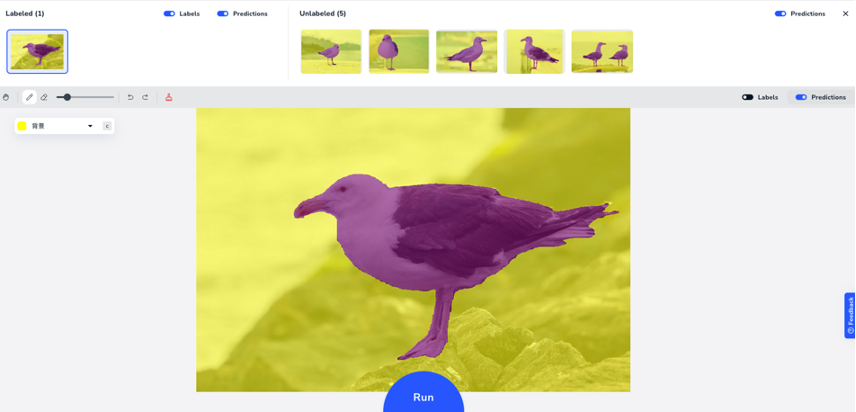
通过上面缩略图其实可以看到,其他图片的预测结果也都更新了下,效果都变好了
个人认为:利用这个功能可以有效降低标注的难度,原本需要精细描画的标注动作,现在只需要做确认和修正即可
Andrew ng 的观点
信息来源于 Visual Prompting Livestream With Andrew Ng
- Visual Prompting 是把 Prompt 应用到视觉领域的一条新的路径,学界也已经有了很多探索(SAM、SegGPT、Visual Prompt tuning等等)
- Visual Promping 的时机已经到来(关于 why now),因为:
- NLP 领域的 Transformer 始于 2017,3 年后的 2020 年出现 GPT-3,5 年后的 2022 年出现 ChatGPT;视觉领域的 Transformer 始于 2020,3 年后的今天出现了 DINOv2、SAM 等(意思是2025年 CV 领域的 ChatGPT 也差不多了)
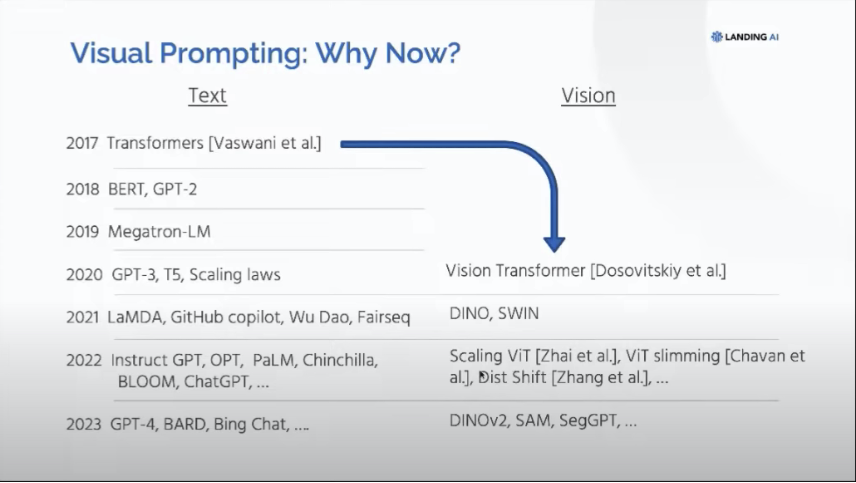
- Transformer + 大量数据 + Pre-Train 的范式驱动
- 训练开始越来越多的使用未标记的数据(或自监督、弱标注),数据可用性的障碍大大降低
- 模型变大 + 数据变大 + 简单的 Prompt 可以帮助 Transformer 在特定任务上实现泛化(个人理解是在说 few-shot/zero shot)
- NLP 领域的 Transformer 始于 2017,3 年后的 2020 年出现 GPT-3,5 年后的 2022 年出现 ChatGPT;视觉领域的 Transformer 始于 2020,3 年后的今天出现了 DINOv2、SAM 等(意思是2025年 CV 领域的 ChatGPT 也差不多了)
其他
Landing AI 的同学说,为了让 Visual Prompting 对客户更实用,他们研究了制造业、农业、医疗、制药、生命科学和卫星图像垂直领域的 40 个项目。分析显示,仅视觉提示就可以解决 10% 的案例,但添加简单的后处理逻辑将这一比例提高到 68% (这里没有详细描述所谓的后处理具体是什么)
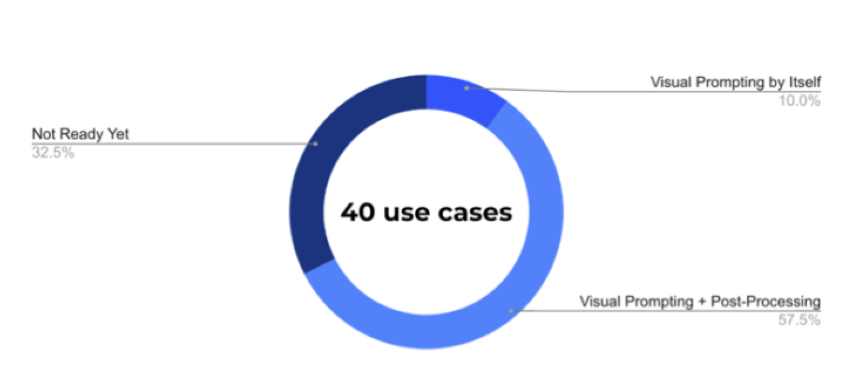
总之,应用前景广阔
III、总结
变化
行业层面
受 SAM 和 Visual Prompting 的影响,标注服务这个行业有从劳动力密集型转变成技术驱动型的征兆
需求层面
Foundation model + Prompt + FIne-tuning 的方式对 Data-Centric AI 有了结构性的需求变化:
- 整体上:对数据的需求总量变大了(预训练),部分数据(微调)的质量诉求变高了
- Pre-Train 阶段:需求的数据量相对较大,但是数据的质相对较低
- Prompt + fine-tuning 阶段:需求的数据量相对(与 Pre-Train 相比)较少,数据的质相对较高
业务层面
人工参与的标注工作在减少,但是人工参与的标注工作质量要求在变高
人员要求的变化:
工程研发人员在后 ChatGPT 时代 Data-Centric AI 中的工作需要对算法有 Know-What 甚至 Know-How 的能力(例如算法模型的任务目标/目标函数是什么)。工程和算法需要进一步提升协作的密切度和深度(Co-Design)。
算法的视角,在大模型时代需要:
- 数据阶段:要和负责这个领域的工程研发做数据集从收集到标注的 Co-Design
- 训练阶段:要和负责机器学习训练服务的工程研发做训练方案的 Co-Design (例如分布式训练的方案)
趋势探讨
Data-Centric AI 从理论到实践走向成熟的驱动力主要有二:
- 学术界突破:学界关注于通过算法来自动化甚至取代数据工程工作, 例如像 CV 领域的深度模型直接学习特征而不是通过数据工程提取
- 商业化实践:产业界更关注量产分工(企业内组织分工)
当前 Data-Centric AI 的升级改变是学界突破所驱动,但是 Data-Centric AI 在人员组织分工上的成熟度提升直至形成行业标准(例如流程化、数据和算法的上下游完全解耦、亦或者 MLOps 相关标准的落地),可能更多的需要优秀的商业化成功案例来驱动(如 Tesla)。
文章作者 1Feng
上次更新 2023-05-20