Prompt Engineering 是一种什么技术?
文章目录
本文其实是关于 Pre-Train + Prompt 在 NLP 领域的实践综述,这里的信息全部来自论文 《Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing》,这是一篇21年7月的综述型论文,当时GPT系列只进展到GPT-3,所以论文内容没有涵盖 instruct-GPT 相关信息。
虽然这是一篇综述但是涉及很多理论和方法细节内容,接下来我的总结会忽略掉一些 NLP 相关方法细节,主要关注核心的一些概念和 常见的 Prompt 相关的范式。
看完这篇文章就能从专业角度理解到底什么是 prompt engineering 了
Ⅰ、NLP 技术演进
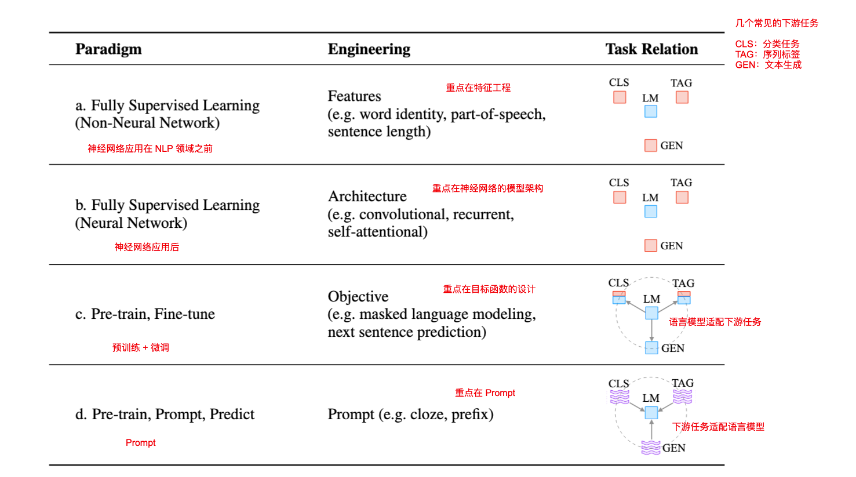
首先作者总结了近几年 NLP 领域技术范式的发展趋势,总体分为了上图 a、b、c、d 四个阶段,其中 2017~19 年 开始出现的 Pre-train + Fine-tune 的方式作者认为是该领域的一次范式革命(a、b 都是基于完全监督学习,但是 Pre-train 已经开始摆脱完全监督)。d 的出现则代表了第二次大的变革的刚刚开始
- a. 非神经网络的 FSL:主要工作总的关注在特征工程,数据挖掘相关
- b. 基于神经网络的 FSL:随着深度学习的应用,主要工作重点关注在神经网络的架构设计,例如卷积设计(CNN)、循环设计(RNN)、注意力机制(attentional)
- c. Pre-train, Fine-tune:重点关注在目标函数设计(个人理解,这个阶段的微调更多会对预训练模型的参数进行调整,来让整个模型的目标更适配下游任务)
- d. Pre-train, Prompt, Predict:这个阶段重点关注在 Prompt 的设计上,是否进行 fine-tune 并不是重点。Prompt 实现了让下游的 NLP 任务可以适配语言模型(基础模型的参数是冻结的)
Ⅱ、Prompt 是什么?
我们以问题的形式对核心的一些概念进行总结
Q1:传统的 NLP 监督学习的形式是什么?
数学描述:
- 输入:x, 通常是文本
- 输出:y, 可以是识别的情感分类也可以是翻译文本等
- 模型:P(y|x;θ), 本质是基于输入 x 来预测 y 的概率模型,θ 是训练学习到的参数
示例:以翻译任务为例 x = “Hyv ̈a ̈a huomenta.” (芬兰语) y = “Good morning” (英语)
Q2:基于 Prompt 的形式是什么?
针对从输入x 获取期望的输出 y 这个问题,我们基于 prompt 来做的流程是:
- Step 1,添加 Prompt
|
|
- Step 2:答案设计和搜索
|
|
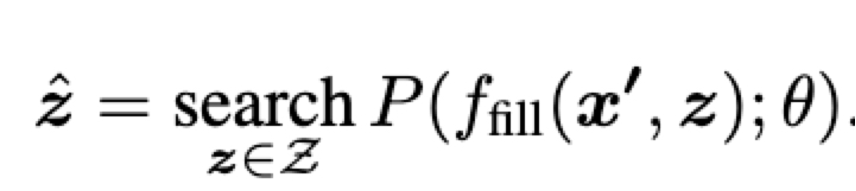
|
|
- Step 3:答案映射
|
|
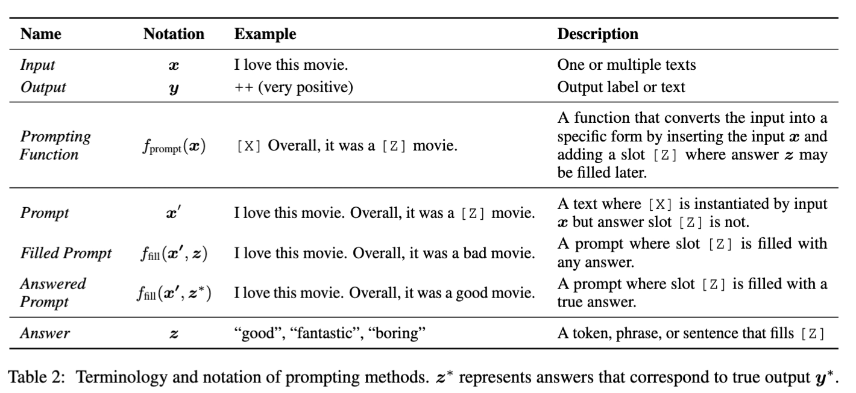
论文中给的完整示例如图:
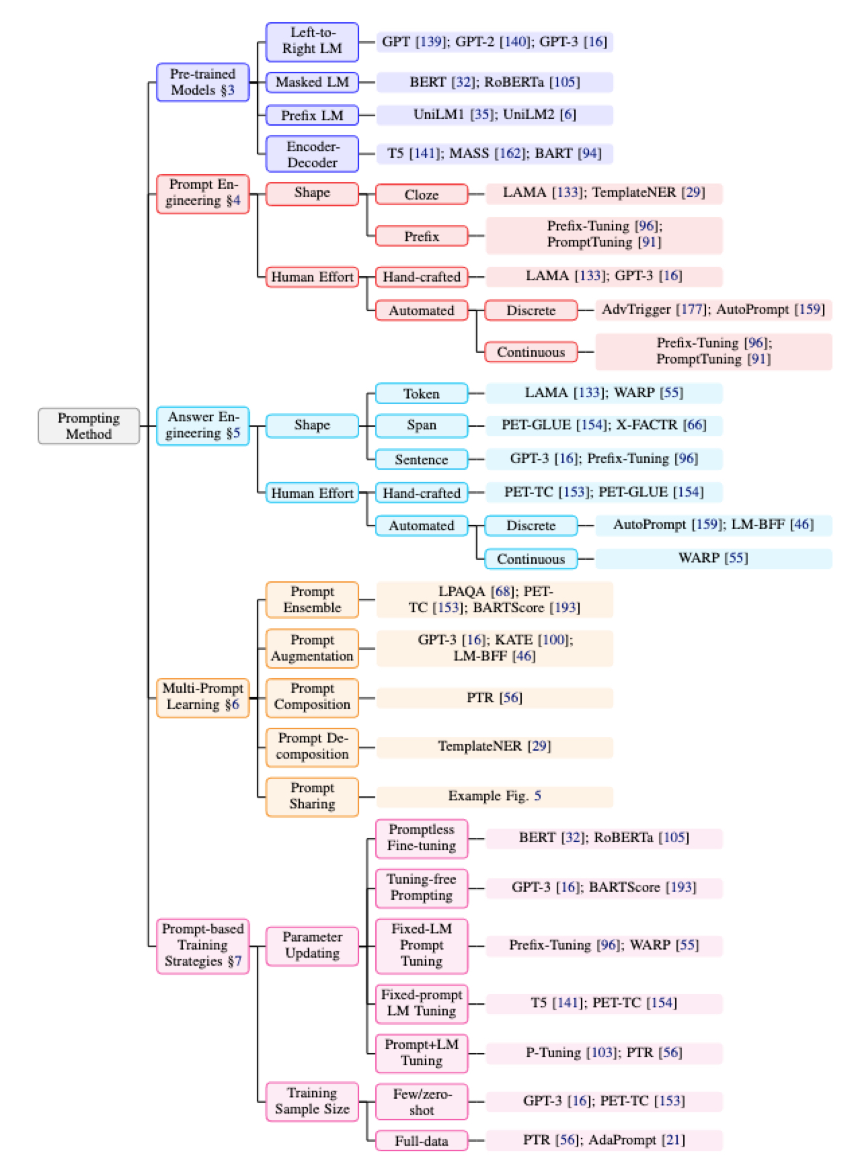
Q3:Prompt 的设计要重点关注些什么?
这里我们主要关注并回答五个问题:
- 如何设计 P(,;θ) ?
- 如何设计 fprompt(·) ?
- 如何设计 z ?
- 如何以复合的方式来设计 fprompt(·) ?
- Prompt 对 fine-tune 策略的影响?
Pre-train model Choice – 如何设计 P(,;θ)
预训练模型有很多类型,主要区别在于目标函数是什么,有的是从左到右的预测(GPT系列),有基于掩码的预测(BERT),不同的目标函数对下游任务有不同的效果,因此对 Prompt 的设计会有不同的要求(个人理解:做 Prompt 设计一定要知道 Pre-train model 的目标函数是什么,设计Prompt 时尽量去适配这个目标才能获得最好好的提示效果)
1. Prompt Engineering – 如何设计 fprompt(·)
- Prompt 类型:根据 Pre-train 模型的目标函数来选择 Prompt 类型,例如GPT系列是从左到右的预测,所以对它们做 Prompt 设计要使用 prefix prompts(前缀式) 的方案。像 BERT 则是使用 cloze prompts(完形填空式的)
- 人工设计 vs 自动化设计
- 人工设计:论文中给出了一些业内案例(如LAMA),未做详细描述
- 自动学习:作者把自动学习分成了两类,一是 Discrete Prompts(离散的),一个是 Continuous Prompts(连续的)。简单理解的话,前者是人能看懂的 Prompt,后者是人看不懂但是模型能懂的(例如 embedding)。 个人理解所谓自动学习本质是把设计 Prompt 这个过程重新转换为了一个传统 NLP 特征工程数据挖掘的问题来解决。
2. Answer Engineering – 如何设计 z
- Answer 粒度:tokens 和 span 适用于分类、关系提取、命名实体识别等下游任务。Sentence 适用于语言生成(如翻译和摘要)
- tokens: Pre-train 模型的字典词袋(简言之就是 pre-train 的训练数据中出现过的所有token集合)中的一个 token 或者 一个 token 子集
- span:短的 multi-token 片段。这些提示通常与完形填空提示(cloze prompts)一起使用
- sentence:一个句子或文件。这些通常与前缀提示(prefix prompts)一起使用
- 人工设计 vs 自动学习:基本思想同 Prompt Engineering
3. 多提示(Multi-Prompt)学习 – 如何以复合的方式来设计 fprompt(·) 业内的大量实践证明多提示(Multi-Prompt)的实践效果显著,所以作者对 Multi-Prompt 技术进行了系统性分类和介绍, 总共分为以下五类方案
-
整合(Prompt Ensembling):
- 图例:
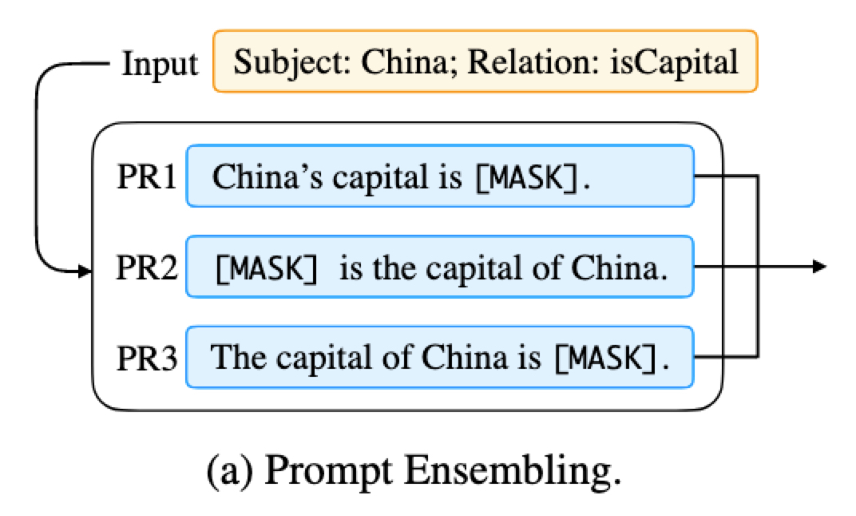
- 说明:使用多个 Prompt(例如有互补能力),然后使用策略对结果进行选择(如加权平均、投票等)
- 图例:
-
增强(Prompt Augmentation):
- 图例:
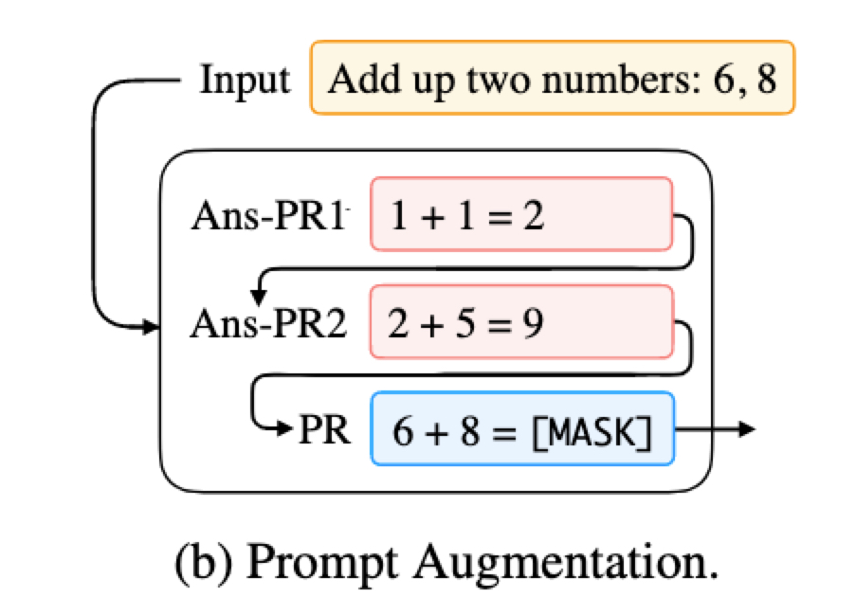
- 说明:其实就是通过 answer-prompt 进行示范学习
- 图例:
-
组合(Prompt Composition):
- 图例:
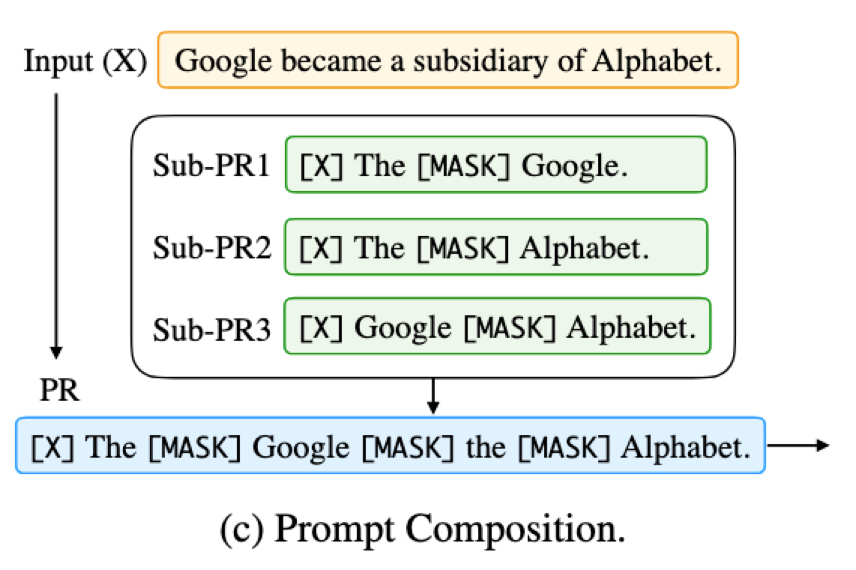
- 说明:示例是一个关系提取的任务,通过设计多个 sub-prompt, 每个sub-prompt 对应一个子任务,例如先识别命名实体,再识别关系,最后定义一个组合 Prompt
- 图例:
-
分解(Prompt Decomposition):
- 图例:
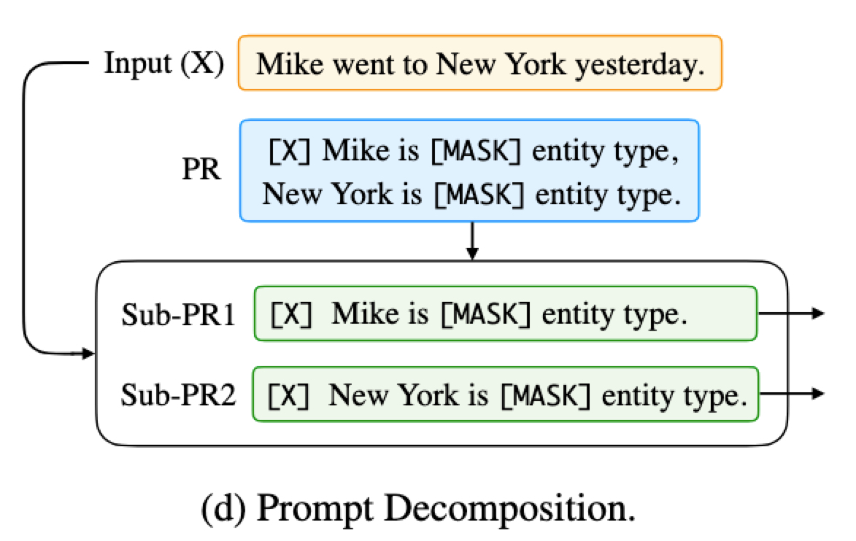
- 说明:组合的反向方式,例如文本中要识别的命名实体太多时,设计一个Prompt可能效果会不好,不如拆成多个 Sub-Prompt
- 图例:
-
共享(Prompt Sharing):
- 图例:
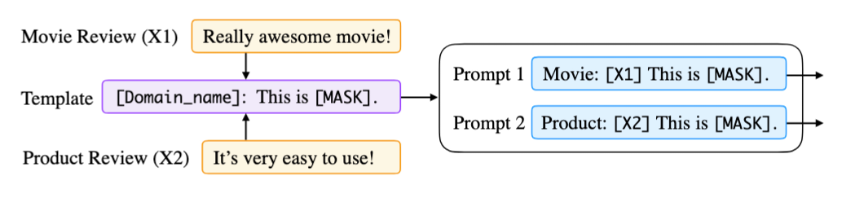
- 说明:如图的案例是通过一个共享的模板,实现在多个不同领域多个不同任务上来进行 Prompt。该领域实践较少,案例有限
- 图例:
4. 基于 Prompt 的训练策略 – Prompt 对 fine-tune 策略的影响?
Prompt 的方式出现之后,针对 Pre-train model 的再训练,主要可以分为以下几种常见策略
| 常见策略 | Pre-train model 的参数策略 | 是否使用 prompt | prompt有无引入额外参数 | prompt 额外的参数是否被 tuned | 优势 | 不足 | 案例 |
|---|---|---|---|---|---|---|---|
| Promptless Fine-tuning | Tuned | ❌ | - | - | 简单,无需设计Prompt | 可能会过拟合,在小数据集上学习不稳定。有可能发生灾难性遗忘(即,丢失掉Pre-Train 得到的一些能力) | ELMo、BERT、BART |
| Tuning-free Prompting | Frozen | ✔️ | ❌ | ❌ | 效率高,无需Pre-Train model 的参数更新过程。因为LM参数保持不变,不会发生灾难性遗忘 | 需要大量的Prompt 工程设计才能实现高精度。上下文较多时会很慢 | GPT-3、AutoPrompt、LAMA |
| Fixed-LM Prompt Tuning | Frozen | ✔️ | ✔️ | ✔️ | 效率高,无需Pre-Train model 的参数更新过程。因为LM参数保持不变,不会发生灾难性遗忘 | 不适用于 zero-shot 场景(作者没解释为什么) | Prefix-Tuning、Prompt-Tuning |
| Fixed-prompt LM Tuning | Tuned | ✔️ | ❌ | ❌ | 对特定下游任务的适配性更强 | 只适配制定的下游任务,对其他类型任务无效。有可能发生灾难性遗忘 | PET-TC、PET-GEN、LM-BFF |
| Prompt+LM Tuning | Tuned | ✔️ | ✔️ | ✔️ | 最具表现力的方法,可能适用于高数据设置。(原文:This is the most expressive method, likely suitable for high-data settings) | 需要训练存储所有参数。容易对小数据集形成过拟合。有可能发生灾难性遗忘 | PADA、P-Tunning、PTR |
- 个人理解:
- 对 Pre-train model 参数的更新,从实践来看很多时候得不偿失,训练成本高+有灾难性遗忘的可能
- Pre-train + Prompt 做进一步 tuning 没有标准的范式,大家都在尝试各种可能。例如是否更新 Pre-train model 的参数以及更新多少并没有明确界限。亦或者除了 Prompt 会引入额外参数,fine-tune 是否还有其他额外参数(个人理解 instruct-GPT 阶段3的PPO也算是引入了额外参数的, 另外 LoRa 的方式也引入了额外参数)
最后附上一张论文中对问题3(Q3)的思维导图:
文章作者 1Feng
上次更新 2023-05-01