后 ChatGPT 时代 Data-Centric AI 的最新思想和方法框架
文章目录
本文内容主要总结自 23 年 3 月份的一篇论文 《Data-centric Artificial Intelligence: A Survey》。作者从必要性、目标、一般方法对 Data-centric 的思想进行了框架性的综述,尤其作者认为 ChatGPT 的成功的重要驱动力就是 data-centric。
作者认为过往论文主要关注在 Data-Centric 的基础和前景上,在相关任务和领域分类方面做得不足,所以才有了这篇框架性的综述。
Ⅰ、概念框架
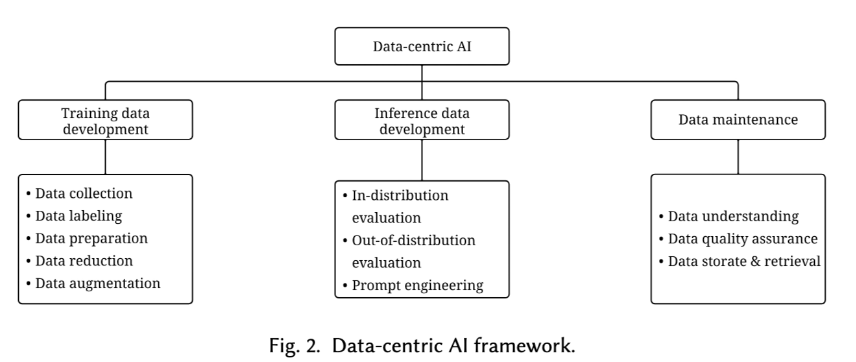
作者将 Data-centric AI 进行了框架性的定义:Data-centric AI 是指为人工智能系统开发、迭代和维护数据的框架。它涉及建立有效的训练数据、设计适当的推理数据、维护数据的相关任务和方法。
Ⅱ、论文思路
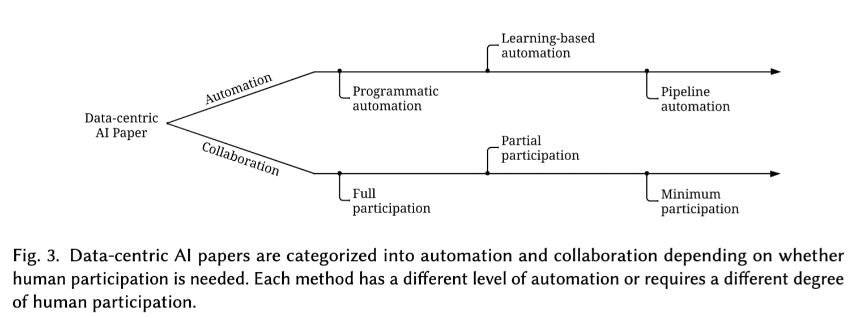
作者对自动化的程度和人工协作的参与程度进行了等级划分,然后按照分类和等级划分对 在 训练数据开发、推理数据开发和数据维护 三个分类领域的相关论文进行了总结性描述。
Ⅲ、重点解读
因为很多内容有点偏传统机器学习特征工程工作和我当前工作领域相关性不大,因此这里我仅分享下 data labeling 和 prompt engineering 两块的相关内容理解
Data Labeling
- 必要性:除了获取 ground-truth 之外,作者重点提到人工标注可以帮助无监督学习来对齐(Align)模型和人类的期望(instruct-GPT 的主要目标就是通过微调来实现 LLM 与 人类用户意图的对齐 Align)。
- 方法策略:主要分为众包标注、半监督、主动学习、数据编程、远程监督 5 中方案,其中半监督和主动学习的核心思路值得进一步去调研,总体来看学界论文提供的方法更关注于具体案例,不太关注通用性和泛化性,直接迁移到企业或者商业化的实际应用场景会有一定难度。
- 难点挑战:核心挑战是在质量、数据量、成本(label quality, label quantity, and financial cost)三者之间进行取舍。另外人的主观性带来的影响也是标注领域的一个难题
Prompt Engineering
作者在这里把 Prompt Engineering 归类到推理数据开发的环节,仅指对已经训练的模型进行 Prompt 设计来评估模型效果(适配下游任务)和解锁模型的特定功能(zero-shot)。
此处主要引出了第二篇论文,这也是我们下一篇文章要总结分享的内容。
Ⅳ、重要观点
摘录了作者在论文结尾处的几个比较引人思考的观点:
- 因为数据越来越多所以 Data-Centric 自动化势在必行,演进会从程序自动化(programmatic automation)–> 基于学习的自动化( learning-based automation) –> 流水线自动化( pipeline automation)
- Data-Centric 中人有着不同程度的参与度,同时人类参与其实是很重要的,因为很有可能人类参与数据工作是确保人工智能系统符合人类意图的唯一途径
- 随着 基础模型 和 RLHF 的发展,模型和数据的设计需要协同进行,二者的界限会越来越模糊(同意作者的这个观点,个人理解未来做数据服务的工程研发可能需要对模型目标函数的设计有 Know-How 的能力)
文章作者 1Feng
上次更新 2023-05-01